
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- EDA
- MSA
- grafana tempo
- Elasticsearch
- Spring
- SpringBoot
- Spring Integration
- feignclient
- traceId
- 회고
- RestTemplate
- Distributed Tracing
- filebeat
- nginx
- kafka
- AccessLog
- logstash
- Sleuth
- Today
- Total
곰돌이형의 개발일지
Nginx Access Log ElasticSearch와 연동하기 (with traceId) 본문
들어가며
백엔드 서버를 운영하다보면, 보통 gateway서버로 nginx를 많이 사용하게 되는데, 사용자들이 어떻게 어디서 접속했는지, 그리고, 에러 발생시 어떤 API 호출로 인해 발생했는지를 파악하기 위해 AcessLog를 파일 형태로 남기는 경우가 많습니다. 하지만 운영하다보면 이슈가 발생할때마다 직접 Nginx에 들어가서 파일을 살펴보기는 쉽지가 않은데요 ㅎㅎ 이럴때 AccessLog 파일을 Filebeat, Logstash를 이용해서 쉽게 ElasticSearch에 내보내서 검색에 용이하게 만들 수 있습니다.
플로우

1. Nginx에서 AccessLog를 파일로 기록
2. Filebeat에서 AccessLog 파일을 tail하면서 Kafka로 Message를 발행
3. Logstash에서 ElasticSearch에 데이터 적재 시도
4. ElasticSearch Ingest Pipeline에서 데이터를 변환해서 저장
사실 이 플로우에서 Filebeat에서 바로 ElasticSearch로 적재도 가능하지만, 대규모 트래픽 발생시 큐잉을 위해 중간에 Kafka, Logstash를 두었다고 생각해주시면 좋을 것 같습니다.
Nginx
nginx에서 accessLog를 기록하기 위해서는 nginx.conf 파일에 accessLog가 저장될 장소와, custom한 log 형식 설정이 필요하다면, log_format을 정의해주시면 됩니다. 저는 아래와 같이 정의하고 사용하였습니다.
http {
log_format main '$remote_addr - [$time_iso8601_p1.$millisec+$time_iso8601_p2] "$request" $status $body_bytes_sent '
'$request_time "$http_referer" "$http_user_agent" '
'$upstream_response_time "$server_name" "$ssl_protocol" '
'$request_length "$upstream_http_x_trace_id"';
access_log /home1/irteam/logs/nginx/access.log main;
}
log_format은 기록하고 싶은 정보들을 이용해서 자유롭게 정의해주시면 되는데, 주로 사용하는 변수들은 다음과 같습니다.
- remote_addr : 요청한 client의 ip
- request : method, url, http version
GET /polarbear HTTP/1.1- status : http status 값
- http_referer : referer
- http_user_agent : user agent 값
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36- request_time : nginx가 요청을 받은 후 client에 응답을 보낼때 까지 걸린 총 시간
- upstream_response_time : nginx가 백엔드 서버에 요청을 보내고 응답을 받을때까지 걸린 시간
- server_name : nginx에서 정의한 server_name
- request_length : 사용자의 요청 크기 (body, header 전부 포함)
- http_${헤더이름} : 사용자가 nginx 서버에 요청한 헤더 내용
- upstream_http_${헤더이름} : 백엔드 서버가 응답한 헤더 내용
Filebeat
nginx에서 accessLog를 파일로 잘 기록하고 있는 것이 확인이 되었으면, 이제 이 파일들을 kafka에 message로 전송하는 filebeat쪽 설정이 필요한데, 관련 설정은 아래와 같이 진행가능합니다.
- input file 관련 참고 링크 : https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-input-log.html
- output kafka 관련 참고 링크 : https://www.elastic.co/guide/en/beats/filebeat/current/kafka-output.html
- output elasticsearch 관련 참고 링크 : https://www.elastic.co/guide/en/beats/filebeat/current/elasticsearch-output.html
filebeat.inputs:
- type: log
tail_files: true
paths:
- ${nginx accessLog 파일 위치}
exclude_files: ['.gz$', '.swp$']
fields:
document_type: ${filebeat 내부에서의 document identifier}
output.kafka:
hosts: ["${kafka 서버 주소}"]
topics:
- topic: '${사용하고 싶은 kafka topic 이름}'
when:
equals:
fields.document_type: ${filebeat 내부에서의 document identifier}
sasl.mechanism: '${kafka 인증 방식}'
username: ${kafka userName}
password: ${kafka user password}
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
이렇게 설정이 되면, filebeat에서는 accessLog 파일을 tail하면서 kafka로 message를 발행하게 되는데, 예시 message는 다음과 같습니다.
{
"@timestamp": "2024-04-01T11:45:42.996Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "8.10.4"
},
"input": {
"type": "log"
},
"fields": {
"document_type": "polarbear_api_log"
},
"agent": {
"ephemeral_id": "087704de-07ec-4cc3-a49b-e7f1a43dacad",
"id": "05219157-089b-4bed-a665-1f1e0397f810",
"name": "${kubernetes pod name}",
"type": "filebeat",
"version": "8.10.4"
},
"ecs": {
"version": "8.0.0"
},
"host": {
"name": "${kubernetes host name}"
},
"log": {
"offset": 29090,
"file": {
"path": "/home1/irteam/logs/nginx/access.log"
}
},
"message": "10.159.42.4 - [2024-04-01T20:45:41.417+09:00] \"GET /polarbear HTTP/1.1\" 200 175 0.015 \"https://www.google.com/\" \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36\" 0.016 \"polarbear.com\" \"IllegalArgumentException\" \"-\" 786 \"867e23c53b2a87ef028afda7e57d503e\""
}
message 부분에 nginx accessLog에서 기록된 부분이 message에 전송되는 것을 확인할 수 있습니다.
Logstash
Logstash에서는 kafka에 발행된 message들을 받아서 elasticsearch에 적재하는 역할을 수행하는데, pipeline 설정은 다음과 같이 진행하였습니다. (logstash.conf)
pipeline 관련 참고 링크 : https://www.elastic.co/guide/en/logstash/current/configuration-file-structure.html
https://www.elastic.co/guide/en/logstash/current/event-dependent-configuration.html
input {
kafka {
bootstrap_servers => "${kafka 서버 url}"
sasl_jaas_config => "${kafka 인증 정보}"
sasl_mechanism => "${kafka 인증 방식}"
security_protocol => "${kafka 인증 방식}"
type => "${logstash 에서의 identifier}"
topics => "${consume할 kafka topic}"
group_id => "${kafka consumer group id}"
client_id => "${kafka consumer client id}"
consumer_threads => ${consumer thread 개수}
codec => "json"
}
}
filter {
if [type] == "${logstash 에서의 identifier}" {
mutate {
copy => {"@timestamp" => "logstashTimestamp"}
}
grok {
// accessLog에서 기록한 형식대로 message 필드에 잘들어갔는지 확인하고,
// 각각 요소들을 elasticsearch field에 매핑하는 과정입니다.
// 참고 : https://www.elastic.co/guide/en/logstash/current/plugins-filters-grok.html
match => { 'message' => '^%{IP:clientIp} - \[%{TIMESTAMP_ISO8601:timestamp}\] "%{WORD:method} %{NOTSPACE:requestPage} HTTP/%{NUMBER:httpVersion}" %{NUMBER:serverResponse} %{NUMBER:responseByte} %{NUMBER:requestTime} "%{DATA:referer}" "%{DATA:userAgent}" (?:%{NUMBER:upstreamResponseTime}|-) "%{DATA:server_name}" %{NUMBER:requestLength} "%{DATA:traceId}" ?' }
}
if "_grokparsefailure" in [tags] {
mutate { }
} else {
date {
match => [ "timestamp", "yyyy-MM-dd'T'HH:mm:ss.SSSZ"]
target => ["@timestamp"]
}
mutate {
// kafka 필드 중에서 불필요한 필드 삭제하는 부분입니다.
remove_field => ["agent", "log", "beat", "source", "offset", "host", "input", "@version"]
}
}
}
output {
if [type] == "${logstash 에서의 identifier}" {
elasticsearch {
hosts => ["${elasticsearch url}"]
user => "${elasticsearch username}"
password => "${elasticsearch user password}"
id => "brandconnect.api.accesslog.logstash"
index => "${elasticsearch index이름, 보통 alias와 같이 사용해서 뒤에 날짜 붙여서 사용}"
pipeline => "${elasticsearch에서 사용할 ingest pipeline (선택)}"
template_name => "${elasticsearch 에서 사용할 template 이름}"
timeout => ${elasticsearch 전송 timeout (단위 : 초)}
doc_as_upsert => ${elasticsearch 에서 upsert 사용 유무}
codec => "${elasticsearch에서 사용할 codec 종류}" // 참고 : https://www.elastic.co/guide/en/logstash/current/codec-plugins.html
ilm_enabled => "${elasticsearch에서 index lifecycle management 사용 유무}"
}
}
}Spring boot Application
전의 글에서 spring boot project에 distributed Tracing을 적용했었다고 전해드렸었는데, spring boot 3에서는 Micrometer library 를 이용해서 더욱더 쉽게 trace가 가능합니다. (링크)
현재 spring boot 3에서는 response에 자동으로 현재 traceId를 반환해주지는 않는데, response에 자동으로 traceId를 붙여주기 위한 코드를 아래에 적어두었습니다. 추후에는 spring boot에서 property로 지원해주지 않을까 싶긴 합니다 ㅎㅎ
@Component
@RequiredArgsConstructor
public class TraceIdInResponseServletFilter implements Filter {
public static final String TRACE_ID_HEADER_NAME = "X-Trace-Id";
private final Tracer tracer;
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
final Span currentSpan = tracer.currentSpan();
if (currentSpan != null) {
HttpServletResponse resp = (HttpServletResponse) response;
resp.addHeader(TRACE_ID_HEADER_NAME, currentSpan.context().traceId());
}
chain.doFilter(request, response);
}
}
이외에도 기록이 필요한 필드가 있다면 해당 class에 header로 추가, nginx access log_format에 추가, logstash.conf에 추가해주시면 됩니다. 추가하면 유용했던 부분은 exception이 나갔을때 exception class 이름이나 사용자 관련 식별자 등이 있었던 것 같습니다.
Elastic Search
ElasticSearch 부분에서의 작업은 필수는 아니나 Ingest Node Pipeline 기능을 이용하면 편리하게 추가 정보들을 ElasticSearch에 적재가 가능합니다. (링크) 필요한 Processor 들을 골라서 pipeline으로 정의해주면 되며, 저는 userAgent, geoip processor들을 사용하였습니다.
- userAgent processor : nginx에서 기록한 $http_user_agent를 version, os, device로 분리해서 기록해줍니다.
- geoip processor : ip를 받아서 지역관련 정보로 변환해줍니다.
추후 더 추가 해볼만한 processor
- urlDecode processor : url decode한 결과로 변환해줍니다.
- URI parts processor : URI를 path, domain, query, port 등으로 분리해서 기록해줍니다.
PUT _ingest/pipeline/polarbear.api.accesslog-pipeline
{
"processors": [
{
"user_agent": {
"field": "userAgent",
"ignore_missing": true
}
},
{
"geoip": {
"field": "clientIp",
"target_field": "geoip"
}
}
]
}
적재가 완료가 되면 elasticsearch 와 연동된 kibana에서 손쉽게 검색이 가능한 구조가 됩니다. 보통 에러로그들에 traceId를 같이 기록하게 되는데, traceId만 알 수 있다면, kibana에서 쉽게 검색해서 어떤 API 호출로 인해서 에러가 발생했는지 찾기가 쉬워집니다.
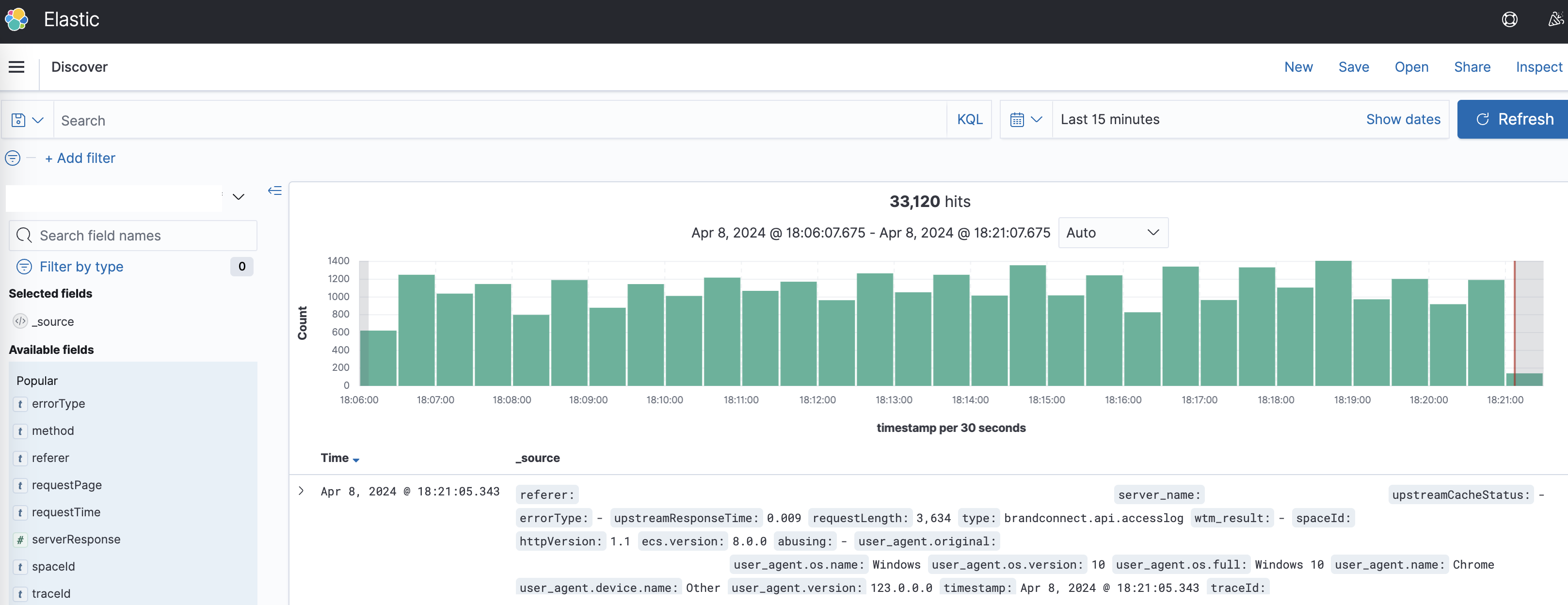
적용 후기
적용하면서 nginx 관련 설정들, filebeat, logstash에 익숙하지 않아서 시행착오도 많이 겪었지만, 결과적으로 accessLog들을 쉽게 찾아 볼 수 있는 도구를 마련해서 에러 대응이나, 사용자 유입 분석에 유용하게 쓸 수 있어서 유의미했던 것 같습니다. spring boot 와 spring cloud gateway를 쓰는 프로젝트라면 한번쯤 적용해보시는 것도 추천드리고 싶습니다. 긴글 읽어주셔서 감사합니다.
'개발 관련 글' 카테고리의 다른 글
| Distributed Tracing 적용기 (5) | 2023.07.30 |
|---|---|
| Feign Client 적용기 (2) | 2022.12.18 |
| Kafka를 이용한 DomainEvent 처리 실패시 처리 방법 (0) | 2022.10.30 |


