
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- feignclient
- Distributed Tracing
- logstash
- AccessLog
- SpringBoot
- filebeat
- Spring Integration
- 회고
- grafana tempo
- RestTemplate
- EDA
- Spring
- traceId
- Elasticsearch
- nginx
- MSA
- Sleuth
- kafka
- Today
- Total
곰돌이형의 개발일지
Kafka를 이용한 DomainEvent 처리 실패시 처리 방법 본문
들어가며
Event Driven Architecture(EDA)로 개발을 하는 경우, event 전달 방식으로 가장 많이 쓰는 플랫폼 중 하나가 Kafka일 것입니다.
보통 한 도메인에서, 추가, 변경, 삭제가 일어나면 이러한 변화를 이벤트로 보내게 되고, 이것을 다른 도메인에서 받아서
이에 대한 처리를 하는 경우가 많을 것입니다.
이러한 처리는 비동기로 이루어지는 경우가 많고, 따라서 처리에 대한 실패도 당연히 있을 수 있습니다. 이런 이벤트 처리에 대한 실패가 있을 때 이것을 어떻게 처리해야 할까라는 고민이 항상 있어왔고, 부족하지만 저희 부서에서 처리했던 방식을 공유하고자 합니다.
이벤트를 받아서 처리하는 유형과 주된 처리 실패 원인
한 도메인의 변경을 내부의 다른 도메인에서 받아서 상태를 업데이트하는 경우
예를 들어서 주문(Order)과 유저(User)라는 도메인이 있고, 주문이 이루어질 때마다 유저에 총 구매금액(totalConsumption)을 저장해놓는 구조라면, 주문이 생성될 때, 주문이 생성되었다는 이벤트를 발행하고, 이 이벤트를 받아서 유저 도메인에 총 구매금액을 업데이트하는 경우가 이 경우에 해당합니다.
처리 실패 원인 : db update시 lock으로 인한 실패 (보통 optimistic locking)
외부 저장소에 상태를 업데이트하는 경우
보통 도메인의 정보에 대한 캐시나, 검색을 위한 데이터를 ElasticSearch나 Redis 같은 저장소에 추가로 저장해놓는 경우가 많을 텐데, 이때 이벤트를 받아서 캐시를 초기화시키거나, 외부 저장소의 데이터를 업데이트하는 경우가 이 케이스에 해당합니다.
처리 실패 원인 : 외부 저장소 시스템의 부하로 인한 read / connection timeout으로 인한 실패
외부 부서에 API로 상태를 업데이트하거나 callback API를 호출하는 경우
처리 실패 원인 : 외부 API 호출이 read / connection timeout으로 인한 실패
이벤트 처리 실패 시 처리 방법
그냥 실패한 이벤트는 버린다!!..
가장 개발자가 신경 쓸 필요 없이 쉽게 적용할 수 있는 방법이나, 데이터의 깨짐을 어느 기간 동안은 감당할 수 있어야 하고, 데이터 깨짐을 주기적으로 복구해줄 수 있는 별도의 로직이 필요합니다. 보통 저희 부서에서는 사용자에게 직접적으로 보이는 데이터들을 주로 다루어서 이 방식은 적용하기 힘들었습니다.
실패했을 경우 될 때까지 반복한다.
보통 이 방법은 kafka commit 방식을 이용해서 진행하게 되며, 실패했을 경우 commit이 되지 않아 offset이 업데이트되지 않게 되고, consumer가 다시 poll을 할 때, 재처리하는 방식입니다.
이 부분은 kafka autocommit 설정을 false로 해두어야 가능한 방식이며, 관리의 어려움으로 인해서 저희 부서에서는 내부 도메인 이벤트에 대해서는 autocommit을 true, 이외 외부 부서로부터 받는 kafka message나 command들에 대해서는 autocommit을 false로 해서 관리를 하고 있었습니다.
만약에, autocommit을 true로 할시 이벤트를 중복으로 처리될 수 있음에 유의하여야 합니다.
추가로, autocommit을 false로 할 때도 주의할 점이 있긴 합니다. 예를 들어서 consumer에서 unchecked exception들에 대해서 제대로 처리를 안 해줄 경우, 모든 consumer가 멈추는 상황이 발생할 수도 있는데, 사실 제가 이 부분 때문에 장애를 한번 낸 적이 있어서.. 그 부분에 대해서는 따로 글로 남기겠습니다..
다른 방법은.. consumer method 안에 resilience4j의 Retry를 이용해서 해당 method에서 자주 일어나는 exception을 catch 해서 재시도하는 방법도 있습니다. 하지만 이 방법은 개인적으로 땜빵(?) 같은 느낌이긴 합니다 ㅋㅋ..
Dead Letter Queue를 이용한다.
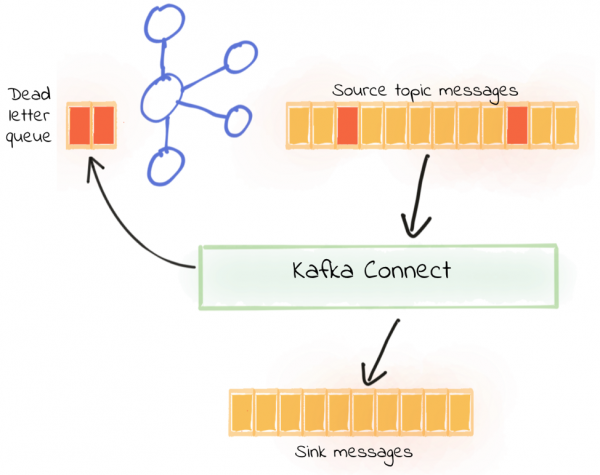
이벤트가 실패 시에, 해당 실패 내역을 dead letter queue에 기록하고, 여기서 실패에 대한 처리를 관리하는 방식입니다.

Confluencer.io에서는 error가 발생했을 때, 이 부분이 retryable 한 것이라면 kafka에 새로 retryable topic으로 발행해서 다른 consumer나 app에서 재실행을 시도하고, 아니라면은 error topic으로 보내서 재실행을 하지 않는 방법을 추천했고, 저희 부서에서 도입했던 방법도 이 방식과 거의 유사한 방식이긴 하나, kafka에 event 처리가 실패했을 때, 새로 topic을 발행하지 않고, db를 이용한다는 점이 달랐습니다.
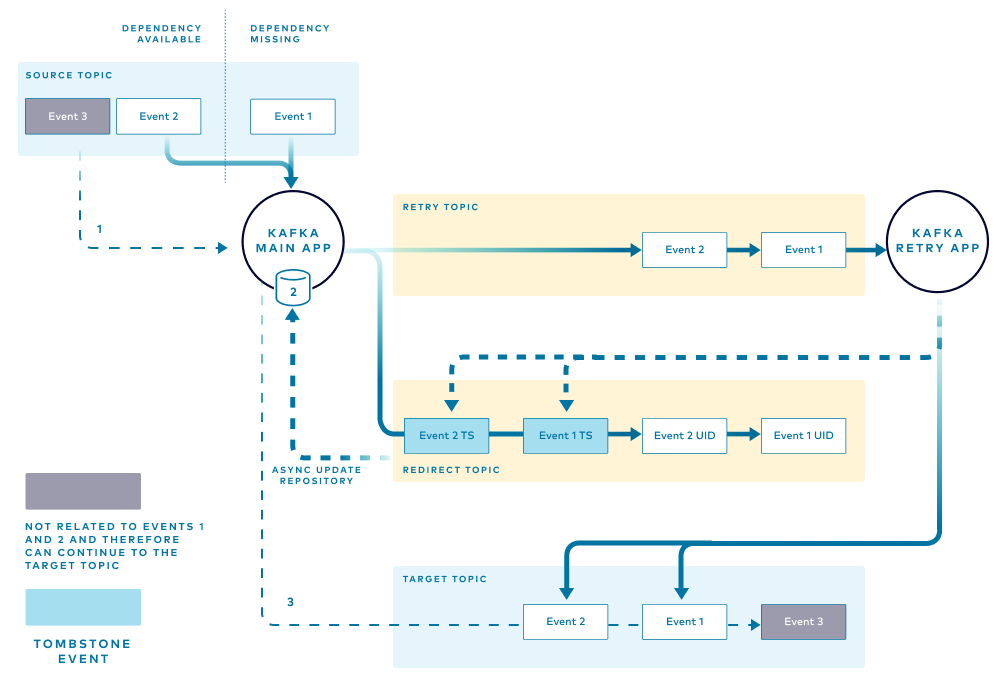
적용했던 실패 이벤트 기록 및 처리 플로우
우선 기본 전제는 모든 kafka message는 내부에서 Message를 상속받는 객체로 변환이 되고, handler들은 특정 package 아래에 위치하여야 하고, method에서 parameter는 무조건 event 하나만 받는다고 가정하였습니다. 간단한 코드는 아래와 같습니다.
public class Message {
private boolean recovery = false;
private int retryCount = 0;
private Long messageFailureLogId = null;
public void changeRecovery(Long messageFailureLogId) {
this.recovery = true;
this.messageFailureLogId = messageFailureLogId;
this.retryCount++;
}
}
public class OrderCreatedEvent extends Message {
}
@Component
public class OrderEventHandler {
public void handle(OrderCreatedEvent event) {
// do something
}
}
그리고 이 이벤트 처리가 EventHandler에서 실패하게 된다면, aspect를 이용해서 db에 간단하게 기록할 수 있습니다.
기록하는 요소는 나중에 실패한 이벤트를 찾아서 복구할 수 있게 (method.invoke(handlerBean, payload) 이용) 실패한 handlerClass, method, payloadClass, payload 등을 기록하게 했습니다.
그 외에 stacktrace는 개발자가 수동으로 복구하게 되었을 때를 위한 용도로 기록하게 했고, retryCount는 이것을 이용하여 retry 횟수의 제한을 두기 위해 기록하였습니다.
@Aspect
@Component
public class MessageHandlerAspect {
private final Storage storage;
@AfterThrowing(
pointcut = "execution(messageHandler 들이 위치하고 있는 패키지..*(Message+)) && args(message)",
throwing = "throwable")
public void logMessageFailure(JoinPoint joinPoint, Message message, Throwable throwable) {
storage.store(MessageFailureLog.newOne(joinPoint, message, throwable));
}
}
@Getter
public class MessageFailureLog {
private Long id;
private String handlerClass;
private String method;
private String payloadClass;
private String payload;
private String stacktrace;
private LocalDateTime occurredOn;
private int retryCount;
// 중간 생략.. newOne으로 joinPoint, message, throwable을 이용해서
// MessageFailureLog를 생성합니다.
}이렇게 db로 기록했을 때의 장점이라고 한다면.. memory에 기록했을 때처럼 pod이 죽거나 사라졌을때도 처리를 이어서 할 수 있다는 점과, kafka에 기록했을때 처럼 별도의 tool 없이도 보기가 편하다는 점, 그리고 현재 처리되지 않은 실패 이벤트의 개수 같은 것을 모니터링에 연동하기가 쉽다는 점이 있습니다. (저희 부서에서는 Grafana와 prometheus, gauge metric을 이용해서, 어떤 이벤트가 실패를 많이 하고, 얼마나 많이 처리가 안되었는지를 모니터링하고 있습니다.)
기존에는 실패 이벤트가 매우 적어서, 실패 이벤트에 대한 복구를 db에서 직접 보고.. 개발자가 이에 대한 처리를 할 수 있었으나, 실패하는 이벤트가 점점 늘어남에 따라서 이에 대한 리소스가 너무 늘어나서, 빠르게 보고 처리할 수 있는 어드민도 만들어보는 등의 노력을 해보았으나, 근본적인 해결이 필요하다고 느껴서 관련해서 개편을 진행하였습니다.
방법은 다음과 같았습니다.
아래와 같은 annotation을 이용해서 event를 처리하는 method에 이 annotation이 붙어있다면, 이벤트가 자동으로 복구가 가능하다는 뜻으로 사용을 하고, 이벤트가 실패했을 때, 다시 시도할 때는 alterMethod를 이용해서 다시 시도를 하거나, alterMethod가 비어있는 경우에는 해당 method로 다시 시도하게 하였습니다.
// MessageFailureAutoRecovery.java
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface MessageFailureAutoRecovery {
String alterMethod() default "";
}적용한 모습은 아래와 같습니다.
이런 alterMethod가 필요한 이유는 보통 이벤트를 실패하고 다시 처리를 할 때, 이벤트의 원본 소스가 변경되었을 수도 있기 때문에, 그대로 원래의 method를 이용해서, Event에 담겨있는 정보를 이용할 경우에 데이터가 꼬일 수도 있을 경우가 있기 때문입니다.
예를 들어서 EnabledEvent, DisabledEvent를 받아서 외부에 그 상태 내역을 업데이트하는 handler가 있다고 가정을 했을 때, EnabledEvent의 처리가 실패해서 상태를 업데이트 못시켰다고 했을때, 그 이벤트에 대한 재처리가 원본 entity가 disable 된 상태 이후에 다시 이루어졌다고 한다면, 원본 entity와의 status가 일치하지 않을 수도 있습니다.
따라서 재처리(복구) 시에는 원본 entity의 상태를 조회하고 이에 따라서 처리가 달라져야 하는 필요성이 있을 때가 많았습니다. 이에 대한 처리를 하고자, alterMethod라는 속성을 두어서 이벤트 재처리 시에는 기존의 method가 아닌, 다른 method를 이용해서 처리를 할 수 있게 하였습니다.
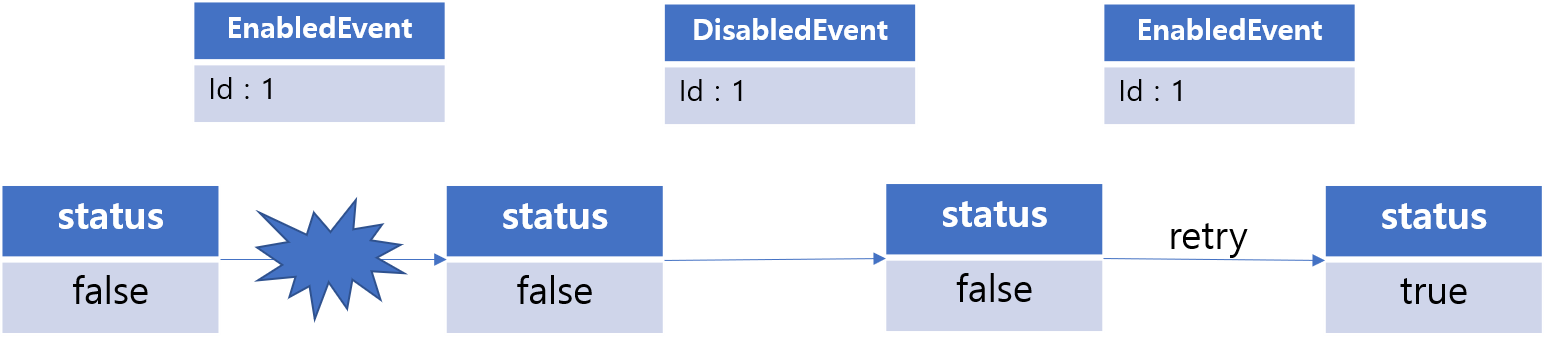
// EventHandler.java
@MessageFailureAutoRecovery(alterMethod = "handleAlter")
public void handle(OrderCreatedEvent event) {
// do something
}
public void handleAlter(OrderCreatedEvent event) {
// do another thing
}이렇게 처리하다 보면.. zero payload에 대해서도 고민이 되기 시작합니다 ㅎㅎ zero payload 사용 시에는 이벤트의 내용을 rest call로 조회 후 처리를 하기 때문에 언제 실행하는지에 상관없이 이벤트 재처리가 기존의 method를 재실행하는 것으로 가능합니다. 물론 이렇게 이벤트 처리시마다, rest call이 일어난다면 성능상으로는 조금 부담이 갈 수도 있습니다.
따라서, 이벤트 처리하는 곳에 MessageAutoRecovery라는 annotation이 붙어있다면, 자동으로 복구가 가능하다는 의미이고, 관련해서 스케줄러를 이용해서 db의 실패한 이벤트들을 순회해서, 자동으로 복구를 할 수 있게 됩니다.
전체 플로우는 다음과 같습니다.

또한 자동으로 복구 처리한 이벤트들은 해당 내역을 로깅 시스템에 남기도록 하였습니다.
결론
해당 플로우를 도입하면서, 각각의 이벤트를 처리하는 로직을 재점검해야 했고, 각각 복구 시에 처리해주어야 할 로직, 원본 entity를 조회할 수 있는 interface들을 만드는데 시간이 많이 걸렸던 것은 사실입니다.
하지만, 한번 정의를 하고 나면 처리에 대한 운영 공수가 확연하게 줄어드는 것을 확인할 수 있었고, 추후 추가되는 이벤트 로직에 대해서도 한 번씩 실패 시의 처리에 대해 고려를 더해보고 추가하게 된다는 장점이 있었습니다.
관련해서 더 좋은 개선방법이나 질문 있으시면 편하게 댓글로 부탁드립니다!!
참고
- 카프카를 잘 모릅니다만 아무래도 멱등성을 보장하고 싶은 건에 대해서 : https://www.youtube.com/watch?v=TtwpO9Pozis
- Error Handling Patterns for Apache Kafka Applications : https://www.confluent.io/blog/error-handling-patterns-in-kafka/
- https://www.confluent.io/blog/kafka-connect-deep-dive-error-handling-dead-letter-queues/
'개발 관련 글' 카테고리의 다른 글
| Nginx Access Log ElasticSearch와 연동하기 (with traceId) (1) | 2024.04.09 |
|---|---|
| Distributed Tracing 적용기 (5) | 2023.07.30 |
| Feign Client 적용기 (2) | 2022.12.18 |


