
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- traceId
- Spring Integration
- 회고
- feignclient
- AccessLog
- nginx
- RestTemplate
- MSA
- Sleuth
- Spring
- Distributed Tracing
- logstash
- SpringBoot
- grafana tempo
- kafka
- EDA
- filebeat
- Elasticsearch
- Today
- Total
곰돌이형의 개발일지
Distributed Tracing 적용기 본문
들어가며
MicroService 구조가 유행함에 따라 여러개로 쪼개져있는 구성요소들, aggregate 기준으로 쪼개진 배포 단위(kubernetes pod이나 vm), 그들 사이의 통신을 담당하는 카프카 같은 메세징 툴, DB 나 ElasticSearch 같은 인프라 요소들까지 백엔드 개발자들이 신경써주어야 할 부분들은 늘어만 가고 있습니다. 그리고 특히 MicroService에서는 서로 다른 컴포넌트들끼리의 비동기적 호출이나 통신으로 인해서 복잡도는 더더욱 늘어가는 추세이고, 이를 logging하거나 monitoring 하는 툴들은 많아지고 있고, 하나의 요청에 대해서 일어나는 모든일에 대한 tracing도 필요성이 늘어가기 시작하였습니다. 그리고 이러한 추세에 대응하는 하나의 솔루션이 Distributed Tracing입니다.
이번 2월부터 Distributed Tracing을 도입하기 위하여, 여러 솔루션들을 조사하고, 도입도 한번씩 해본 결과를 공유해보려고 합니다. 도입하면서 저의 부주의로 인해서 큰 장애도 한번 일으켰었고, 도입과정에서 배운점들도 많아서 이 글을 읽으시면서 Distributed Tracing을 적용하실때, 조금이라도 도움이 되었으면 합니다.
Distributed Tracing 이란?
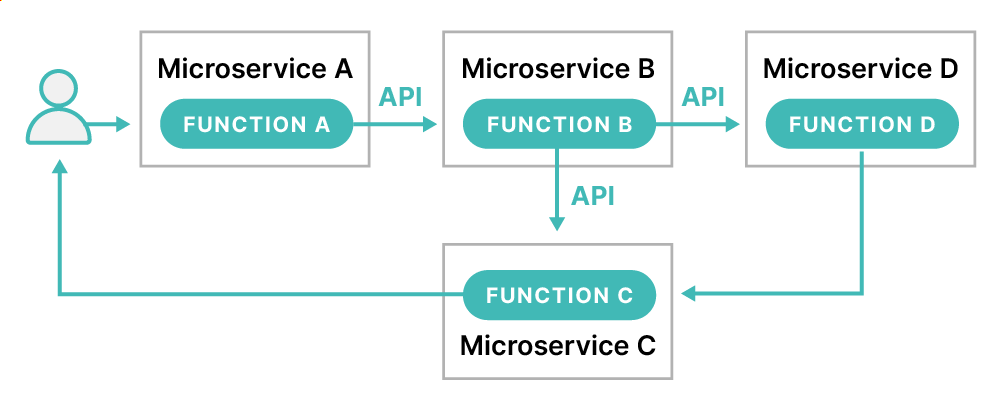
Distributed Tracing이란 사용자나 시스템으로 부터 시작된 request가 분산 클라우드 환경을 통해 전파되는 흐름을 추적하는 것을 말합니다. 위의 예제 그림에서 보면, 사용자의 요청이 서비스 A에 요청되면, B, C 서비스에 요청이 전파되고, 그 후에는 사용자에게 응답이 전달되는 과정 전체를 추적하는 것을 말합니다. 서비스 끼리의 통신은 꼭 http call에 국한된 것은 아니고, kafka, grpc 같이 비동기 방식도 포함됩니다.

보통 Distributed Tracing의 가장 작은 단위는 Span으로 불리며, 보통 서비스에서 수행하는 행동 하나와 같습니다. 예를 들어서 그림1)에서 functionA, A에서 B로 API요청, FunctionB 등이 Span 하나로 로깅되게 됩니다.
Trace는 Span들의 집합이며, 하나의 요청으로 일어난 Span들이 하나의 Trace로 묶이게 됩니다.
보통의 Distributed Tracing 솔루션들에서는 TraceId와 SpanId들을 두어서 Trace 단위로 Span들을 하나의 화면에서 모아볼 수 있게 구현되어 있습니다.

Distributed Tracing의 솔루션들은 보통 크게 4가지의 구성요소로 나누어져 있는데, 구성요소들은 다음과 같습니다.
1. Client Instrumentation : Application에서 spanId, traceId를 붙여주고, 다른 Application으로 요청이 전파될때 traceId를 붙여주는 역할을 수행합니다. (kafka나 http call에서는 header를 붙여주는 방식으로 전파를 하게 됩니다.)
2. Pipeline / Agent : span들, trace들에 대한 정보를 집계하는 서버로 전달해주는 역할을 수행합니다.
3. Backend : Agent로부터 전달받은 span들과 trace들을 저장하고, UI에서 검색이나, 집계가 가능하게 관리하는 역할을 수행합니다.
4. Visualization : Trace 단위로 span들을 쉽게 확인할 수 있게 UI를 제공하는 역할을 수행합니다.
솔루션들 비교
먼저 솔루션들은 오픈소스들과, 유료로 제공되는 APM들이 있었는데요. 오픈소스쪽에서는 Zipkin, Jaeger, ElasticSearch Apm, Grafana Tempo 등이 있었고, 유료 APM 중에서는 Datadog, Honey Comb, Kamon, logit.io, New Relic, Splunk 등이 있었습니다.
물론 유료 APM들이 여러 대시보드들을 제공하고, UI도 깔끔하고 기능도 많았기에 끌렸지만.. 회사의 긴축정책..으로 인해 오픈소스로 한정해서 살펴보기로 하였습니다.
추가로 이 비교는 저희 프로젝트가 Spring Boot 기반 프로젝트라서 이 기반으로 비교한 것임을 염두해주시면 좋을 것 같습니다.
Client Implementation
이 부분에서는 spring에서 가장 유명한 spring-cloud-sleuth library가 있습니다. (링크)
sleuth는 http, feign, mysql, kafka, redis, rsocket 등의 spring에서 사용하는 거의 모든개발 요소들간의 추적을 지원하고, 특히 propagation 지원이 잘된다는 것이 특징입니다. 예를 들어서, http요청시나, kafka message 수신시에, 헤더로 propagation이 되기 때문에 어떤 사용자의 요청으로 부터 시작이 되었는지를 추적이 가능합니다.
또한 sampling 기능 지원과, 여러 개발 요소들을 추적하는 Tracer에 대해서 interface를 제공해서 이를 구현하면 custom한 label을 추가를 쉽게 할 수 있는 것이 큰 장점입니다.
보통 ElasticSearch Apm 같은 Apm 들에서는 각자 구현한 Client Implementation과 Agent들을 동시에 지원하고, 간단하게 java option 같은 것으로 사용할 수 있게 지원하는 편입니다. 하지만 spring환경에서는 sleuth만큼 광범위한 범위를 커버하지는 못하는 것 같았고, 커스텀 할 수 있는 부분이 적어서 저희 부서에서는 spring-cloud-sleuth를 사용하게 되었습니다. 추가로 회사에서 제공하는 에러 알림 시스템에서 sleuth의 traceId를 받아서 기록해줄 수 있다는 점도 선택시에 큰 영향을 주었습니다.
Pipeline / Agent
client 부분을 sleuth로 쓰기로 먼저 결정하니, 선택할 수 있는 Agent 즉 전송방식은 크게 3가지로 좁혀졌습니다.
http, kafka, 그리고 prometheus를 이용한 방식입니다.
먼저 http 방식은 세부적으로 보면 여러가지로 나눌 수 있겠지만, trace 하나마다 application에서 http call로 전송하는 방식, 그리고, trace 여러개를 한번에 모아서 비동기로 전송하는 방식이 있었습니다. 또한, 전송 protocol은 여러가지가 있지만 현재는 OpenTelemetry에서 제공하는 protocol이 대세로 잡고 있는 분위기 입니다. http 방식은 결국에는 전송시에 서버의 자원을 소모하기에 application의 cpu나 memory에 영향을 주게 되는 것은 단점입니다.
다음으로 kafka 방식은 zipkin에서 제공하는 기능이었는데, kafka message안에 trace에 대한 정보를 넣고, zipkin server에서 이 message를 consume해서 server에 저장하는 방식이었습니다. kafka 방식이 비동기로 전송이 가능하기에 상대적으로 http 방식보다는 application에 성능적인 저하를 초래하지 않고, 적용이 가능하여 매력적으로 보였었습니다.
마지막으로 prometheus 방식은 spring 3.0부터 지원하는 방식인데 (링크), actuator에 trace정보들을 담고, prometheus에서 주기적으로 이를 scrape해서 저장소에 저장하는 방식입니다. 이 방식도 application에 영향을 거의 주지 않아서 매력적이지만, spring 3.0을 적용해야 한다는 점이 조금은 부담으로 여겨져서, 이번에 신규로 적용되는 프로젝트에는 이렇게 적용해보기로 결정하였고, 적용후에 추가로 글 작성해보겠습니다. >_<
Backend & Visualization
여기까지 오고나니, Zipkin과 Grafana Tempo 간의 결승전이 되었었는데요. 승부는 의외로 Backend & Visualization에서 결정되었습니다.
zipkin은 저장소로 in-memory, mysql, elastic-search, cassandra 를 사용할 수 있고, 보통 elastic-search를 많이 사용하는 것 처럼 보였습니다. in-memory와 mysql은 리얼환경에서는 사용하기 힘든 옵션이고, elastic-search나 cassandra를 사용했어야했는데, 추가로 관리해야 되는 인프라에 대해서 조금 걱정이 있었습니다.
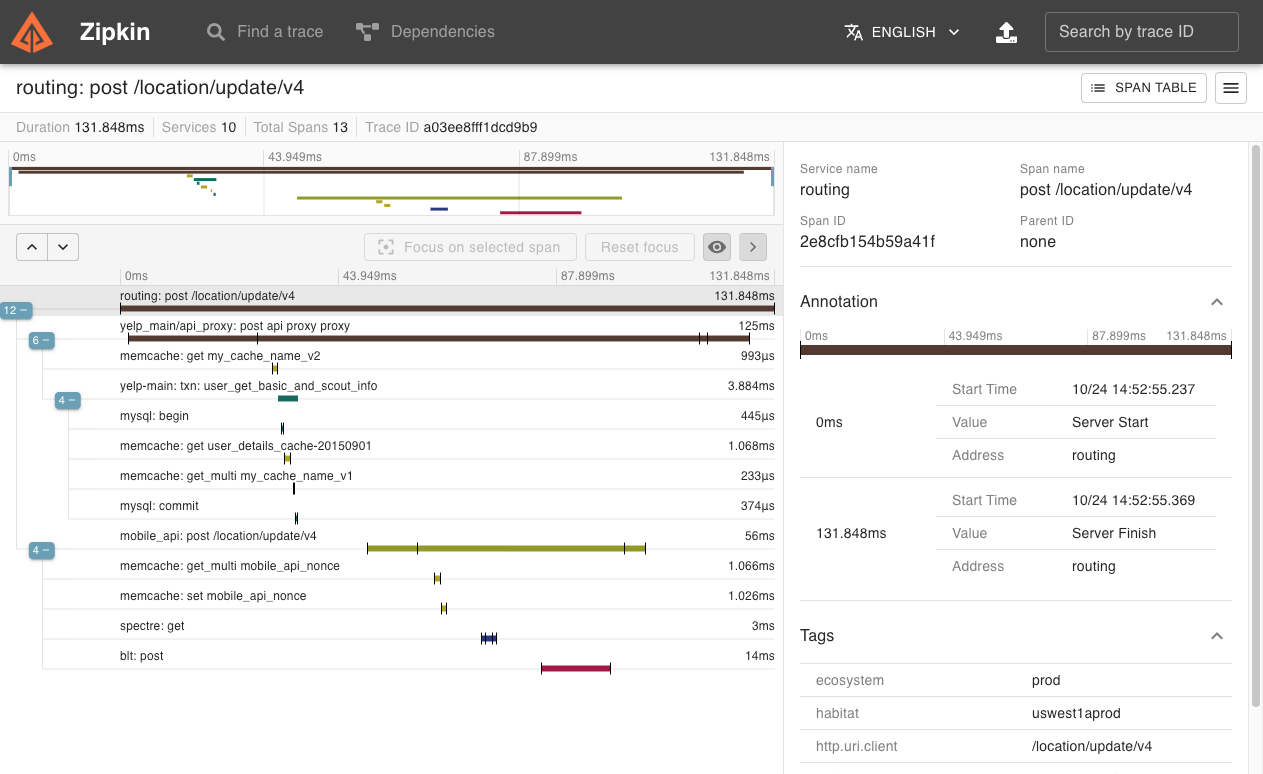
아래 두 사진은 zipkin의 UI 인데요. Trace를 한눈에 볼수 있고, span마다 클릭해서 자세한 내용을 볼 수 있는 UI는 꽤 괜찮다고 느껴졌었습니다. 하지만 검색화면에서 검색할 수 있는 요소들이 traceId, tag, duration정도 뿐이라서 조금은 부족하다고 느껴졌었습니다. 추가로.. 사소하지만 Grafana Tempo의 UI를 보고나니, span을 클릭할때 오른쪽으로 화면이 펼쳐지는 것도 살짝은 불편하다고 느껴졌었습니다.

Grafana Tempo는 저장소로 간단하게 object storage(ex. ceph, amazon s3) 를 사용할 수 있고, grafana에서 개발한 loki라는 저장소를 사용할 수 있었습니다. 상대적으로, elastic-search 보다는 kubernetes 환경에서는 저장소를 persistant volume으로 손쉽게 관리할 수 있는 점이 장점으로 다가왔었습니다.
추가로 Grafana Tempo 에서는 traceQL 이라는 trace나 span을 검색할 수 있는 쿼리를 사용할 수 있게 지원하는데, 이를 이용해서 trace들을 더 세부적으로 검색이 가능합니다. (링크)
또한 metric-generator를 이용해서 span들이 쌓이고 있는 상태에 대한 지표라던가, 서비스간의 호출을 한눈에 볼 수 있는 service graph 등도 기록이 가능하게 쉽게 볼 수 있습니다. (링크)



최종 선택은 Sleuth + Grafana Tempo 로 되었는데..
결국 여러 솔루션들간의 비교를 하고나서 내린 결론은 지표를 만드는 부분에 대해서는 sleuth를 이용하고, Backend 및 UI는 Grafana Tempo로 결정하게 되었습니다. 하지만 아직 남아있는 숙제가 하나 있었으니.. 그것은 현재 저희가 사용하고 있는 Spring 버전은 2.7으로 Agent부분으로 prometheus를 사용하지 못하는 부분이었습니다. 남은 Agent 방식은 http 방식이었는데, 성능 테스트 결과 application에 성능저하가 너무 일어나서 적용하기가 무리인 상황이었습니다.
그렇다고 Backend 및 UI부분을 Zipkin을 사용하기에는 Grafana Tempo로 이미 눈이 높아져 버린 팀원분들을 설득하기는 매우 어려웠었는데요.. 그래서 조사를 더욱더 많이 해본 결과 spring experimental project로 spring-cloud-sleuth-otel이라는 프로젝트가 있다는 것을 발견하였습니다. 이 라이브러리를 사용하게되면, http보다는 가벼운 프로토콜인 grpc로 이용해서 batch로 trace 들을 모아서 grafana tempo 저장소에 전달을 할 수가 있었습니다. (링크)
이 라이브러리를 발견하고, 전에 하였던 성능테스트도 다시 진행해보았는데, 다행히도 application에 성능저하를 거의 일으키지 않았고, 이를 이용하여 배포를 진행해보기로 하였습니다.
추가로 저희 부서에서는 수많은 GET 요청들 까지 모두 trace하기에는 가용량이 부족하니, 데이터의 변경이 있는, GET을 제외한 요청들만을 trace하기로 결정하였고, trace 불필요한 kafka message들, 스케줄러들은 interface 구현과 spring.sleuth.span-filter.span-name-patterns-to-skip property를 이용해서 구현하였습니다.
순조롭게 진행되는 듯 했으나..
배포는 부서 내에서 가장 복잡한 로직이 있고, trace할 필요성이 가장 많다고 생각되는 컴포넌트 하나를 대상으로 먼저 진행되었습니다. 배포 진행 후 일주일 동안 memory나 cpu 등에서 이상이 있는지 확인하였고, Grafana Tempo 서버에서도 trace들을 잘 받아주는지 확인하였습니다.
이상이 없는 것을 확인 후에, 전체 컴포넌트 대상으로 적용범위를 확대하였고, 순차적으로 배포를 진행해나가던 와중이었습니다. 저희 부서 내에서 가장 많은 트래픽이 몰리는 권한인증 관련 서버에 적용해서 canary 배포를 했었는데, old pod을 제거하자마자 신규 pod들로 트래픽이 집중되었고, allocation stall 현상이 다수 발생했었습니다. 그 결과로 인증 관련 기능이 제대로 작동을 하지 않았고, 큰 장애로 이어졌었습니다. 빠르게 이전 버전으로 롤백을 진행하였고, 다행히 이전버전으로 롤백하자 마자 사태는 종료되었습니다.
이후에 원인을 파악해보았는데, 생각외로 원인은 간단하였습니다.
@ConditionalOnClass(name = "io.opentelemetry.api.metrics.GlobalMeterProvider") 를 만족하지 않아서 trace를 전송하는 것이 batch로 이루어진것이 아니라, SimpleSpanProcessor를 이용해서 단건으로 전송되었고, 이 때문에 메모리를 다수 점유하게 되어서 벌어진 것이었습니다. (링크)
BatchProcessor를 사용하기 위해서는 io.opentelemetry.api.metrics.GlobalMeterProvider 이 class가 예전 버전의 opentelemetry library에 포함되어있는 class라 opentelemetry 버전을 내리거나 application에서 직접 batch로 SpanProcessorProvider 를 bean으로 생성해주면 되었었는데, 저희는 후자의 방식을 사용하였습니다.
추가로 겪었던 이슈
Tempo에 너무 많은 데이터나, 큰 trace를 보내게 되면 limit에 걸려서 받아주지 못하는 경우가 있습니다. (링크)
이때는 tempo 설정중에 아래 부분들을 적당한 값으로 수정해주시면 됩니다.
- ingestion_burst_size_bytes
- ingestion_rate_limit
- max_traces_per_user
- max_bytes_per_trace
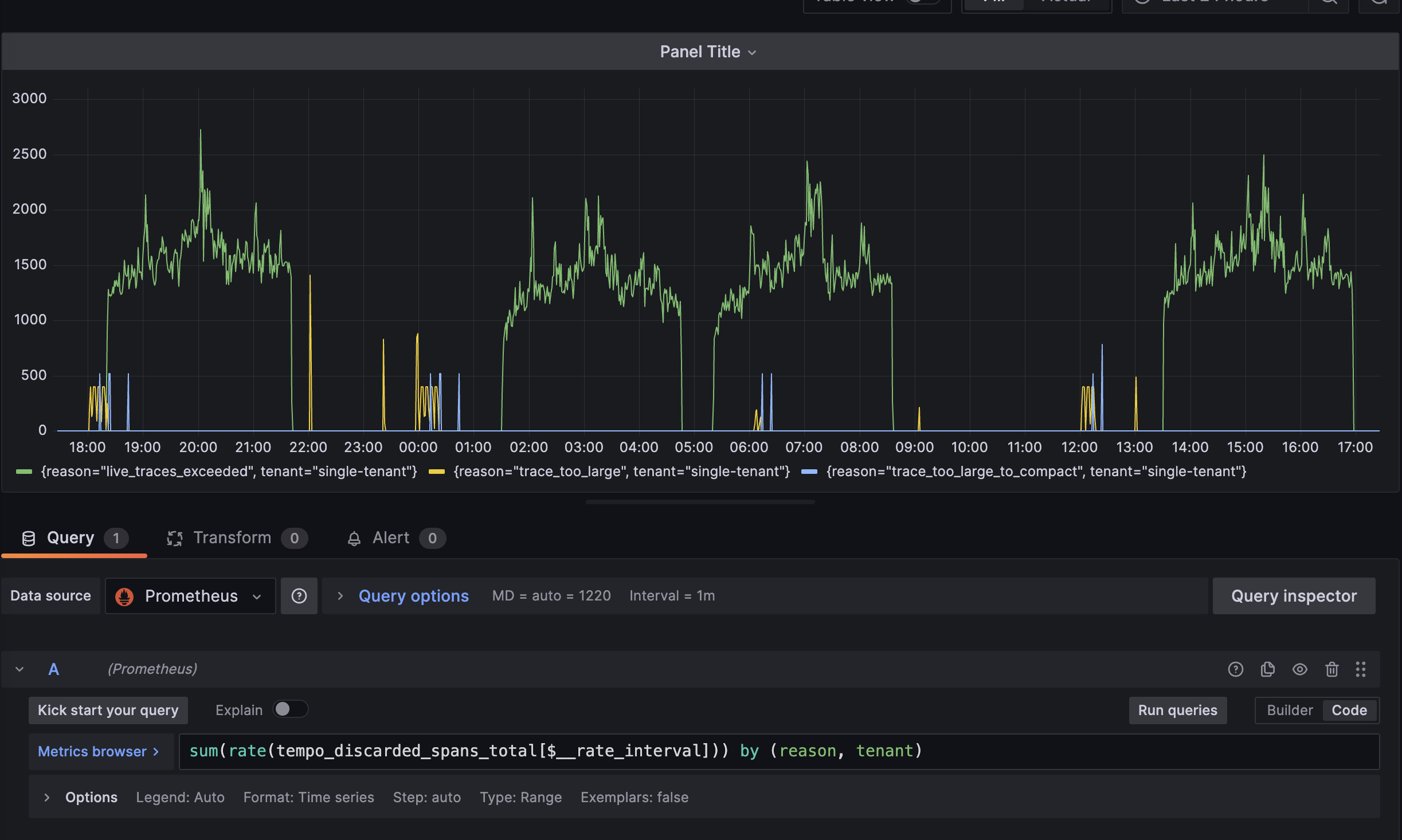
이런 것들이 일어나는지 인지를 하기위해서는 아래와 같이 tempo와 연결된 prometheus에서 tempo_discared_spans_total 지표를 살펴보시면 좋습니다! 보통 한 스케줄러에서 많은 일들을 하는 경우에 이런 경우가 많이 일어났었습니다.
마치며
항상 새로운 것을 도입하기 전에는 기존의 서비스에 영향이 줄만한 부분들을 확실하게 파악하고 테스트하는 과정이 충분하게 필요한데, 이번에는 충분히 검증을 했다고 간주한 오만한 생각이 결국에는 큰 장애로 이어졌던 것 같습니다. 앞으로 새로운 기술을 도입하기 전에는 더욱더 많은 검증과 크로스체크가 필요한 것을 뼈저리게 깨달았던 계기 같습니다.
힘든 과정을 거쳐서 도입한 Distributed Tracing인 만큼, 앞으로 사용하게 되면서 느끼는 장점이나, spring 3.0 정식으로 지원하게 될 부분들을 추가로 도입한 후에 추가로 글 작성해보겠습니다.
지금까지 Distributed Tracing의 장점으로는 예전에는 분리된 MicroService 컴포넌트들 간에 흐름이 코드안에서 찾으면서 따라가야만 보이는 것들이 많았는데, 지금은 UI로 이런 부분들을 손쉽게 볼 수 있으니, 어떤 요청으로 인해서 어떤 것들에 영향을 주는지 손쉽게 파악할 수 있는 점이 큰 장점인 것 같습니다. 부서내 컴포넌트들이 점점 늘어가고, 관리가 힘들어진다면, Distributed tracing은 선택이 아닌 필수라고 생각될 정도였습니다.
그리고 Grafana Tempo의 장점이라고 한다면 여러 metric을 정말 많이 지원하고, 검색도 정말 세부적으로 가능하기때문에, 이를 이용해서 Dashboard들을 하나하나 유용하게 만들어 간다면 팀운영에 정말 도움이 될 것이라 생각됩니다.
긴글 읽어주셔서 감사하고, 많은 댓글 부탁드립니다!!
'개발 관련 글' 카테고리의 다른 글
| Nginx Access Log ElasticSearch와 연동하기 (with traceId) (1) | 2024.04.09 |
|---|---|
| Feign Client 적용기 (2) | 2022.12.18 |
| Kafka를 이용한 DomainEvent 처리 실패시 처리 방법 (0) | 2022.10.30 |


